
Do we have a useful aging clock?
13 years after the first 'aging clock' was published we're still measuring mouse lifespan and unable to run human aging trials. What's missing?

I believe aging biomarkers is the most important project we can undertake to increase progress on longevity. But when I talk about this publicly the most common reaction is “Don’t we already have those?” or “Oh yeah I already did an age test I’m [real age -3]”.

It’s hard to get people excited about a problem they think is solved. If I pull them into a nuanced discussion of biomarker requirements (that they’re rarely in the mood for), I can sometimes get to “Oh ok makes sense, but sounds kind of boring”. Progress?
Norn Group is always happy to do boring work that’s required for impact. But we also want to articulate why that work matters, and I’m hoping this post can do that. By reading it I want you to realize that yes biomarkers are important, that yes biomarkers exist, and that there’s work to be done before biomarkers are actually useful.
Imagine a world where everyone has a watch, but still look up at the sun to keep track of time. Clearly something is off, even if people say their watches are great.
A large part of the confusion is that the term ‘aging clock’ is currently being applied to a wide range of different tools. Measuring tools with different purposes by the same metrics doesn’t help us improve. So we’ll go through these uses, assess how we’re doing for each, and then call attention to certain actions we should take today if we want a real path to using clocks to find therapies to treat aging in humans. We’ll see that, counterintuitively, some of those require focusing less on human clocks.
(Note that I’m following convention and using ‘clock’ instead of the more accurate ‘biological age test’ throughout this essay, in part to emphasize that what we call clocks are research-grade tools that we can’t yet rely on to test biological age1).
Why do we need clocks?
I’ve previously emphasized iteration speed as a driver of progress, and one that biotech struggles with. Software companies can write and test new products daily and distribute them at the speed of light. Biotech can only iterate at the speed of life. And the goals of the longevity field are particularly slow: Preventative medicine means an inevitable delay between treatment and confirmation, and successfully extending life means that answers arrive even later. The ability to predict the future using measurements today would change these dynamics completely.
Even so, the impact of good biomarkers is probably underestimated: Not only would we cut a year or two off every mouse study on longevity around the world, increasing the pace of research by up to 25%2. Not only would this also reduce the cost of research by another 25% or more, allowing more to happen in parallel. Not only would an early measure convert aging clinical trials from untenable to comparable to what we do for individual diseases, which may be required before the first trials for aging get launched. Shaving years off trials also preserves patent life and reduces the cost of capital, increasing investment in new medicines.
And on top of this, decreasing costs and delays increases momentum for the field: There are many unanswered questions in longevity, like whether a single treatment can reduce biological age across the body or whether we need combinations of treatments, how to design trials with the best signal per cost, and how to dose and deliver different treatments. We won’t have answers to most of these until we try potential solutions and find out what we’re missing. Faster and cheaper iterations means we can put down more puzzle pieces faster, as things get filled in it becomes easier to solve the next piece. So validated biomarkers/clocks will increase not only the rate of progress in longevity, but also the rate of acceleration.
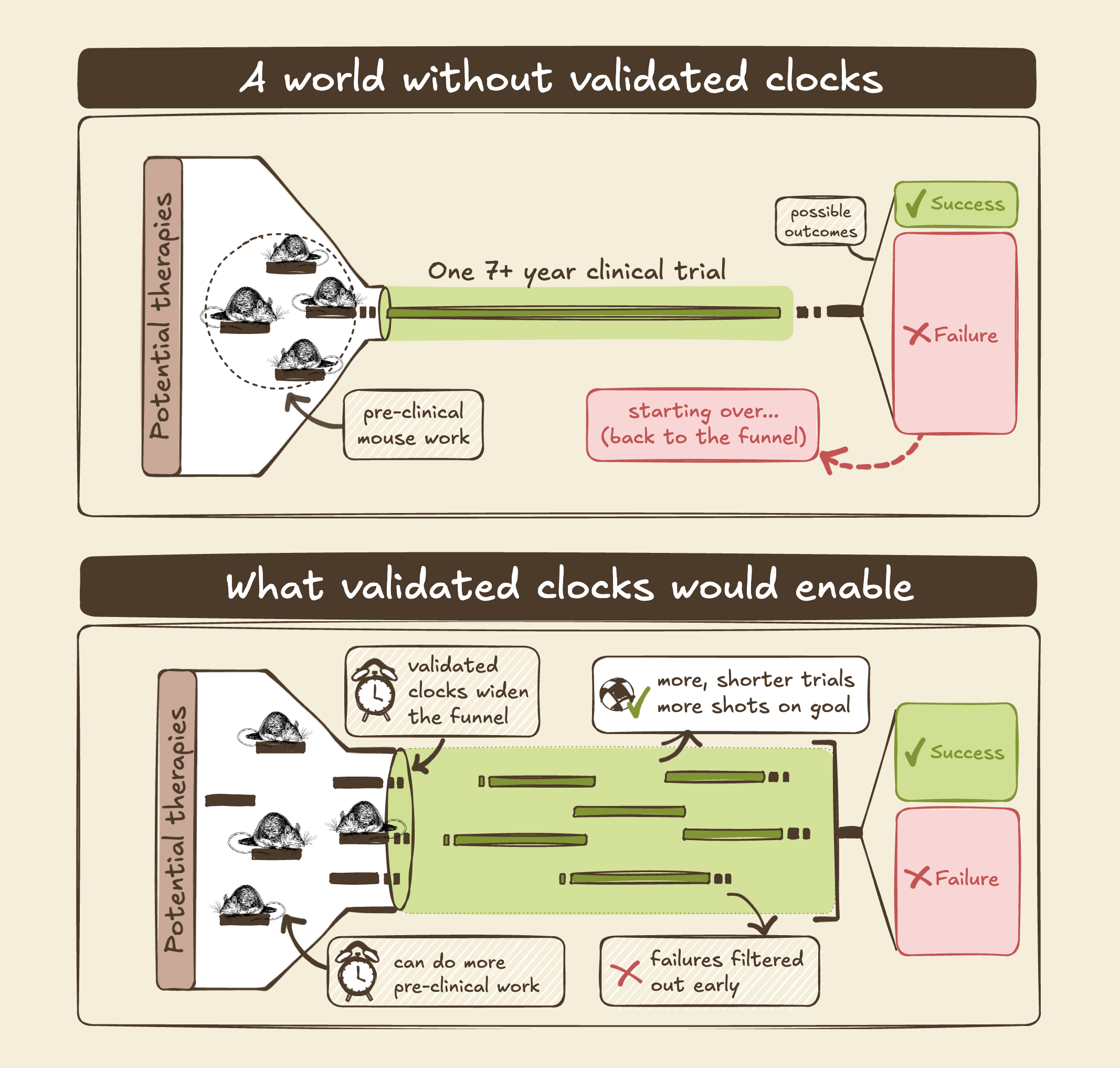
What we talk about when we talk about clocks
The idea of a single number distilling the whole aging process is delectably simplifying, and that apparent simplicity part of why the ‘clocks’ concept has gotten so much attention3. We might be able to do that, but at the moment our clocks actually measure a wide range of things. And you can imagine that different uses with different design choices all have their place: Is surgery the best way to diagnose cancer? It’s the most accurate, but also quite invasive…
So, we currently have many ‘aging clocks’ that don’t do the same thing. One way to distinguish clocks is what they’re physically measuring (proteins, DNA methylation, …), but this only matters for determining the constraints of trying to make the clock do what you want. What you want to do is what drives decision-making and sets the goalposts. So let’s look at the intended uses for aging clocks:
R&D: You want to do experiments to understand biology and/or find new candidate therapies, and avoid waiting for aging and death as your readouts.
Consumer health optimization: You want to monitor and probability optimize your health. You’ll do measurements at regular intervals, and change your behavior by whether the clock goes up or down.
Design and interpret clinical trials: You want to select who goes into your trial, or identify people who respond better or worse to some treatment, purely for your own learning.
FDA approval: You want to run a clinical trials and get Accelerated Approval from the FDA based on lowering clock scores, ahead of showing improvements in mortality or disease.
Medical care: You want to run tests know whether prescribed medicines and behaviors are working. Wrong results are a big deal, as they could lead to wrong treatments (and, in the US, lawsuits galore).
It’s telling that today, aging clocks are frequently used for the first two purposes but ~never for the last three (where the cost of being wrong is high). Evidently, people in charge of these costly decisions do not think that aging clocks are ready to use.
Today, there are hundreds of research papers using clocks, at least a dozen consumer products you can buy, and zero cases of biopharma running a clinical trial with a clock as the endpoint.
Why is that? The original 2012 clocks were strictly correlates to chronological age, which is not a very useful thing to estimate. But later clocks have been trained to predict mortality, frailty, and other important outcomes. So the answer must be that we can’t yet trust their predictions.
Where are the clocks failing us? Let’s look at the most important metrics for clocks:
Accuracy: Does the clock accurately measure the true biological state with low variance? If two simultaneous measurements can vary by a decade, the clock has limited utility.
Responsiveness (Precision/Recall): Does the clock only record the past, or does it update if a treatment or intervention modifies what we want it to measure? And for the latter, does it sometimes respond when it shouldn’t?
Interpretability: Do we know the physical/biological reality that the clock is measuring, or is it a black box? If not, it’ll be hard to convert answers to actions.
Stability: Does the clock change depending on time of day, or whether you have the flu? If it mostly tells you about your current state, you’ll need multiple measurements to understand trajectories.
Applicability: Does the clock work across sexes, genetics, or even different species? If not, or if unknown, your answer may be meaningless in some contexts.
Cost: Maybe everything works, but it’s too expensive to be worth it.
Just optimize everything! But in practice there are tradeoff between improving each metric, especially while also keeping costs down. If we want clocks to help us, we have to think about which parameters are important for our purpose.

Accuracy is straightforward, and of course restricts use cases where precision is needed. One important consideration is that ~every clock is created using data averaged across many individuals, so every result is a probability of living longer, not an exact death year.
Norn Group’s mission depends on new therapies with strong impact on biological aging, for which the Responsiveness metric is important. Good Responsiveness means avoiding false positives and negatives. A biological measure of a subset of what happens with age could predict well under normal conditions, but could fail to respond to an intervention that affects a different aspect of aging (and yields benefits). Conversely, an intervention could act directly on the biological measure without affecting aging itself, e.g. a clock tracking DNA methylation of a specific part of your genome might go to zero if you remove that DNA with CRISPR, but that wouldn’t mean you’re actually younger.
To properly assess Responsiveness, behavior must be characterized across a wide range of interventions; responding correctly to one or two doesn’t tell us how often false positives/negatives occur. For example, consider a frequently used clinical test, simply measures how far patients can walk in six minutes. This is used to assess e.g. heart function, because low oxygenation reduces your capacity. But although it does correctly respond to improved heart function, Responsiveness is moderate at best: giving patients caffeine or other stimulants will increase your walk distance without helping your heart.
Your watch might track time perfectly, but turning the dial back doesn’t mean you did time travel.
High stability means measuring states, low means measuring rates. Rates are more actionable, but more prone to confounding factors. High Stability is important if we want to get robust results from infrequent measurements, e.g. in an annual checkup. But high Stability also means slower responses to intentional interventions. So if you want to know whether a lifestyle change or therapy changed your current aging rate, lower Stability can be better as long as Responsiveness and Accuracy are high.
FDA surrogate biomarkers must be mechanistically plausible, so low Interpretability is a no-go for this purpose. (Notably, ~every clock based on DNA methylation has low Interpretability). Interpretability is also important for R&D: you could use a black box measure to screen treatments, but you couldn’t use the outcomes to guide what interventions to test or what experiments to use to confirm results. Clinical use will also require showing Applicability spanning intended use cases4.
A specific type of Applicability is cross-species, i.e. does your clock work both in (human) patients and in animal models used for early drug discovery (e.g. mice). If not, it’s hard to do controlled experiments to test how your clock behaves or to transfer lessons from early research to e.g. clinical trial design. But cross-species Applicability puts additional constraints on what you can measure.
Going back to our different use cases, we can see that different metrics matter more or less for each one5:
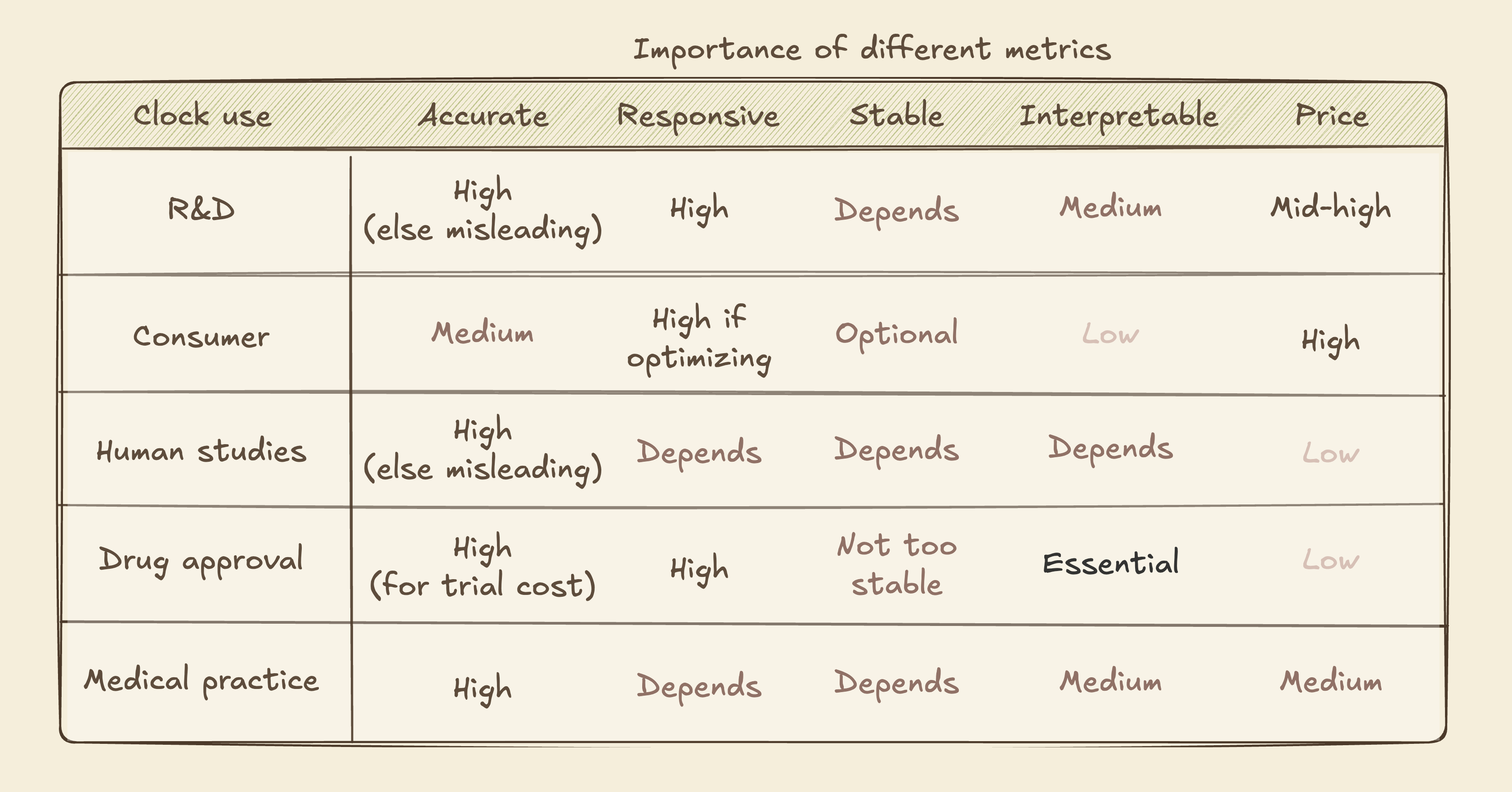
Are we there yet?
As we suspected from current real-world use, we are not there yet:

Accuracy is OK, but known to vary with time of day and between tests. There are questions as to whether it’s better than simpler measures. Price (hundreds to a thousand dollars) is mostly OK although a magnitude lower would be helpful.
Responsiveness across many interventions remains untested for ~all clocks, because the data to do so properly hasn’t been generated. We don’t have human-validated aging therapies (as in, shown to extend healthy human life), so every human-only clock lacks the ground truth data needed to broadly test Responsiveness. Without this, pharma companies can't make clinical trial decisions and doctors can't use clocks for treatment guidance. For observational studies this isn’t a huge issue, and indeed we see clocks used in observational clinical work and for consumer longevitainment.
Interpretability is near zero for the majority of clocks, and low for the rest6. They might be trained on an interpretable endpoint, like a frailty index or time of death, but what’s being measured is a molecular change (like methylation of a specific part of your chromosome) that doesn’t have any known link to the endpoint. This again makes the clocks less useful for clinical trials and drug development - if you see a clock go down in certain patients but don’t know why, how does that change your actions? Some newer ideas like clocks for specific organs add some interpretability, and I expect the field to shift towards tests for specific biological (dys)function7.
How did we end up with consistent gaps in these two metrics? I believe the main cause is a decision to focus on human clocks. Clocks that work well in humans are obviously most attractive (and splashy), so the decision makes some sense. But human-only makes it much harder to generate new data to validate predictions or fill gaps for clock development.
Very few research labs have funding to run human studies, even observational ones. So we end up making more and more clocks using the available data. Some add nuanced information, like organ-specific aging, some correct for technical noise in a new way. This is useful work, but does not address the key bottlenecks (unknown Responsiveness and Interpretability) required to mature clocks from consumer and academic use into tools for finding therapies and running clinical trials.
“A man with a watch knows what time it is. A man with two watches is never sure.”
Time to move forward
Bold research has given us a proof of concept that the aging process can be tracked with molecular measurements. We should appreciate that. And we should acknowledge that we won’t benefit much from talking about clocks’ potential for practical uses until we’re able to properly benchmark the required performance metrics. So let’s decide on the uses we think are most valuable, and make sure we build the infrastructure to track where we are now and whether we’re improving.
To eventually use some kind of biological age test as a clinical trial endpoint, we have to shift our focus to interpretable measures with mechanistic links to aging and disease. One example of this would be to build predictors based on proteins in blood samples, rather than DNA methylation patterns. Proteins have known functions, so even if you first build your predictor on pure regression you can tease apart the role and value of each component and arrive at something mechanistically interpretable. Building clocks without a path to mechanistic interpretability can still be useful for R&D (and entertainment) purposes, so I’m not saying we should avoid this entirely. But human clinical use is important enough that major efforts ought to be compatible with that goal.
To use clocks for finding powerful therapies for aging, we have to robustly benchmark Responsiveness. There are two ways to do this: We can go directly to human-trained clocks, as is the current trend, which allows optimization towards the final clocks right away. But the optimization will probably take multiple decades: First we need to identify more than one working aging therapy in robust trials, without the benefit of guidance from clocks (since they haven’t yet been validated). It’s unlikely that this happens in less than ten years. Only then do we see whether the current clocks are good enough, and if not start making new ones. Once something fits existing data well, the FDA will likely still ask for a fresh trial for confirmation.
Alternatively, we develop cross-species clocks and take advantage of known ways to modulate aging in mice to test Responsiveness. If our current clocks are inadequate, more work using mouse models can iterate quickly to reach something promising. At that point we can use the clocks in human trials for putative aging therapeutics, while also using them to speed up the search for more therapies. FDA endpoint use won’t be feasible until at least a couple of trials have happened. It will still take years before we’re fully confident in clocks for human use, but not decades. I believe this is the better approach.
Beyond having ground truth data, the best way to benchmark is third-party hosted (for impartiality), standardized (for interoperability), and publicly accessible, similar to ImageNet (which enabled computer vision) or CASP (which enabled AlphaFold etc).
Funding such a clock assessment program is the highest leverage in longevity. Between accelerating R&D and eventually enabling human trials, good clocks are very much worth pursuing. The future we want is public benchmarking of performance for the most valuable uses, norms that all serious work submits to this benchmark, and thus iterative improvement towards better and better predictions of future health.

Appendix 1: Existing efforts & resources
The Biomarkers of Aging Consortium is the most active organization on this topic. The group contains many of the academics working on aging clocks and some biotechs, but notably not people from biopharma developing biomarkers. The consortium is focused almost entirely on human aging clocks. They have published a great set of papers for going deeper on the topics discussed here:
Biomarkers of Aging for Identification and Evaluation of Longevity Interventions
Challenges and Recommendations for the Translation of Biomarkers of Aging
They also launched a competition for benchmarking, using existing data.
TranslAge & Biolearn have benchmarked current clocks on a set of useful parameters.
The ARPA-H PROSPR program to find aging therapeutics includes a biomarker component, with the intent of using new trials to start validating them. Relying on new therapeutics working makes this opportunity to refine biomarkers rather uncertain.
Their approach involves the ‘Intrinsic Capacity’ concept, which could be an effective way to quantify aging as a medical outcome and is now part of WHO’s ICD-11 codes.
The TAME trial for metformin as an aging therapy similarly has a biomarker component, but again relies on uncertain therapeutic effects to get meaningful signal. The trial has also been seeking funding for a number of years, so far without success.
Mining samples from past, completed, clinical trials is perhaps more likely to succeed, though these trials are in diseased patient populations and did not focus on lifespan.
A number of longitudinal human datasets exist that cover a lot of what would be needed for biomarker developed, but with gaps especially for FDA-recognized surrogate endpoints. We’ve outlined those here.
The best ground-truth data on lifespan effects is the NIA Intervention Testing Program. Unfortunately this program did not collect blood samples to allow, but the results can be used to inform what data to collect for a clock assessment program.
For the nomenclature enthusiasts: “Clocks“ is not a very accurate descriptor for what we’re talking about, insofar as time passes uniformly for different people. In terms of analogies, ‘odometer’ would be more apt. And many of the measurements we’re describing are really speedometers rather than odometers. My expectation is that as we mature biological age tests for different uses we’ll move from universal to use-specific names.
Assuming most papers on longevity take 3-4 years to produce, but also that the lifespan studies aren’t always gating the paper.
It’s telling which longevity concepts (based on actual science) have reached the public discourse: “Telomeres at the end of DNA shorten until you die”, “zombie cells appear with age and removing them makes you younger”, “mitochondria, the powerhouse of the cell". All analogies that anyone can visualize, all single-factor explanations.
We can see some relationships between parameters, further affecting design choices.
Accuracy is hard to estimate in low Stability territory, because we can’t easily distinguish accurately reading a rapidly changing reality compared to variable measurements of a stable reality.
And Interpretability helps estimate Applicability, Responsiveness, and Stability. If Interpretability is low, each of these traits must be estimated with data for any new use case. This is why the FDA considers Interpretability essential for surrogate endpoints, as illustrated by the walk test example: Because the test is interpretable, the false positives for stimulants can be identified and explained.
There are additional considerations around predictions that are accurate at individual versus group level, whether we’re predicting mortality or specific diseases, and what kind of actions we want to enable. I’ll leave both these a full discussion of tradeoffs between these, including considerations for predicting
Some consumer tests sharing the ‘clock’ label are really composites of common measurements your doctor might order, like blood pressure and inflammatory markers. These are highly interpretable, but have been around for a long time and don’t predict as well as we’d like to (as evidenced by lack of clinical adoption).
A very cool feature of collecting high-dimensional data like proteomics as the foundation is that multiple different clocks, for example predicting different organs’ function or biological mechanisms, can we built from a single measurement. This modularity allows both continuous improvement and computational iteration without new physical costs.
I totally agree that we need more intervention data; learning clocks on observational data is deeply problematic and the intervention data that we have are few and far between. See also Ageing Research Reviews 110 (2025) 102777 (https://doi.org/10.1016/j.arr.2025.102777)